El día que el DNS Technitium me mostró un malware - BotNet BillGates (Elknot)
 Ni la primera semana de haber vuelto de la licencia… todo desconectado estaba, tratando de retomar el ritmo. Me preparo un mate, arranco la jornada tranquilo y, casi por costumbre, ya que hacia un par de semanas habia puesto en producción el DNS Technitium se me da por entrar al para ver cómo venía la red.
Ni la primera semana de haber vuelto de la licencia… todo desconectado estaba, tratando de retomar el ritmo. Me preparo un mate, arranco la jornada tranquilo y, casi por costumbre, ya que hacia un par de semanas habia puesto en producción el DNS Technitium se me da por entrar al para ver cómo venía la red.
Grave error… o gran acierto.
Empiezo a mirar el top de dominios consultados y aparece algo que no cerraba para nada. Dominios raros, completamente fuera de lo habitual. Ahí ya me hizo ruido.
Siguiente paso: ver qué equipos estaban haciendo esas consultas.
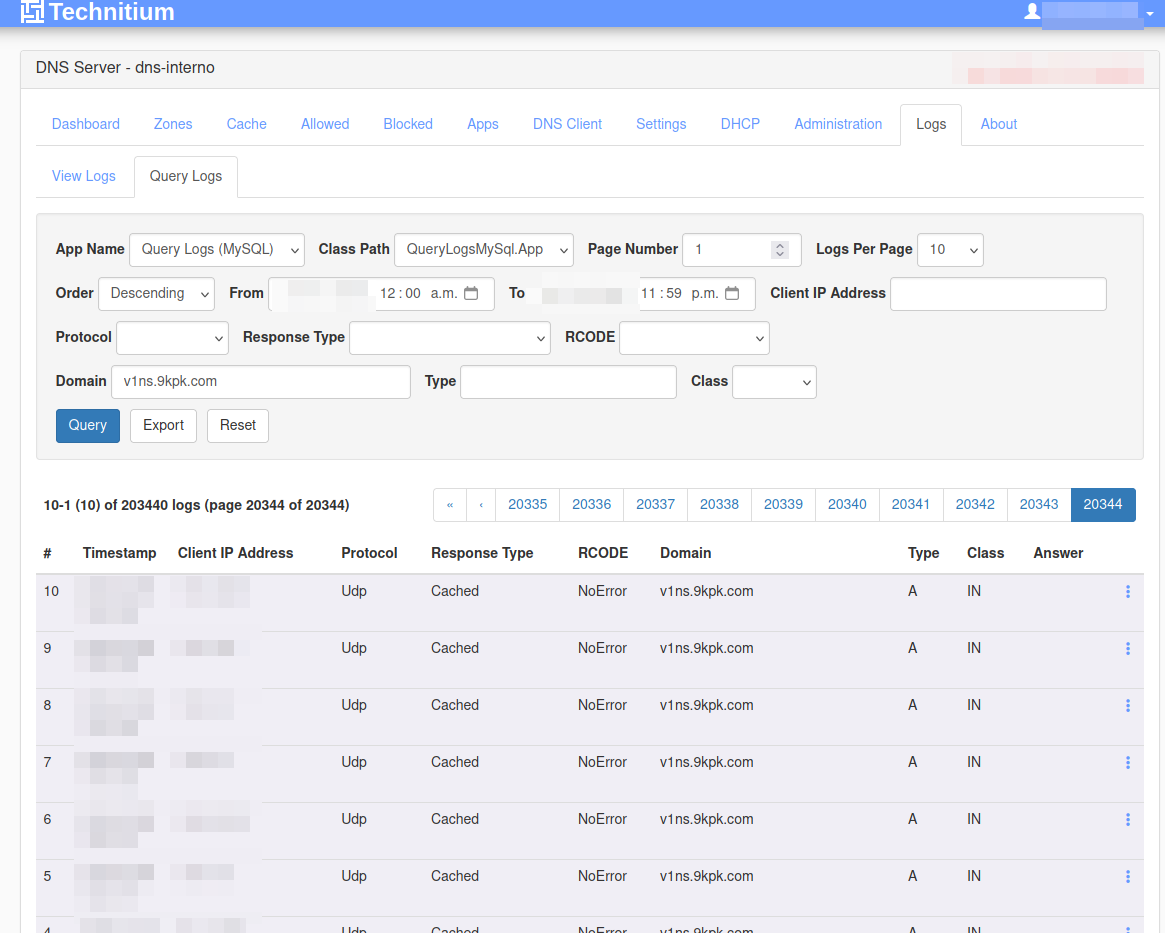 Cuando veo las IP… servidores internos.
Cuando veo las IP… servidores internos.
Ahí fue cuando pensé: “okey bueno, arrancó el baile”. Todo indicaba que podía estar frente a algún tipo de malware o actividad maliciosa dentro de la red.
Y a partir de ese momento, empezó el análisis.
Punto de partida: consultas DNS sospechosas
Detecto consultas recurrentes a un dominio que no me cerraba por ningún lado:
v1ns.9kpk.com
Primera reacción: bloquearlo directamente desde el DNS.
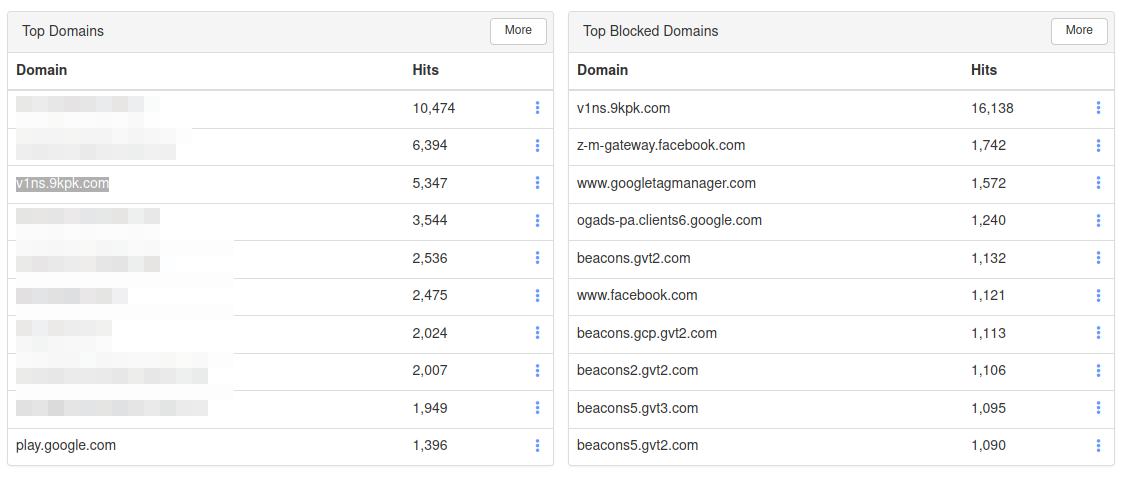 A los pocos minutos… boom.
A los pocos minutos… boom.
Pasa al top de dominios bloqueados.
Ahí ya no era casualidad.
Mientras tanto, algo no me cerraba en la cabeza:
estos servidores no tienen o no deberían tener salida a internet, y además son servicios internos, no expuestos.
Y sin embargo… estaban consultando dominios externos.
Con esa contradicción dando vueltas, me conecto al servidor infectado para analizar qué estaba pasando desde adentro.
Análisis en servidor comprometido
Antes de meter mano, lo primero fue entender dónde estaba parado.
Los servidores afectados corrían sobre:
Sistema operativo: CentOS 5.10
Kernel: 2.6.18-371.12.1.el5.centos.plus
Y acá ya aparece un dato no menor… estamos hablando de sistemas legacy, sin soporte y con múltiples vulnerabilidades conocidas.
Con ese contexto, todo empezaba a tener más sentido.
Entonces arranco con lo básico para ver ese trafico hacia el servidor DNS interno:
tcpdump -i any port 53Y lo que veo confirma la sospecha:
Consultas tipo A hacia dominios raros
Respuestas NXDOMAIN (dominios inexistentes)
Consultas PTR asociadas
Comportamiento típico de manual:
Intentos de contacto con servidores de comando y control (C2)
Validación de conectividad
Posible uso de DGA (Domain Generation Algorithm)
Y ahí aparece el segundo actor en escena:
2.ip1100.com
Listo, ya no era uno solo.
El tráfico malicioso estaba apuntando a:
v1ns.9kpk.com2.ip1100.com
Buscando el origen
Empiezo a revisar servicios en el servidor… y algo no cuadraba.
cat /etc/init.d/selinux
En CentOS 5 ese servicio no existe.
Ahí había algo raro.
Veo el contenido:
#!/bin/bash
/usr/bin/bsd-port/knerlBien!! Sospechoso de acá a la china esto ya era otra cosa.
Buscando referencias, aparece el primer indicador claro:
Un binario llamado knerl, intentando hacerse pasar por kernel.
Clásico intento de camuflaje.
El problema: no lo podía matar
Y ahí empezó la parte frustrante.
Buscaba el proceso:
ps awx | grep knerlNada.
Con top… nada.
Horas pasando… y el proceso seguía ahí, generando tráfico.
Probaba matar otros procesos, volvía a mirar con tcpdump…
seguía sucio.
Ya era personal.
Rootkit en juego
Investigando más a fondo, todo apuntaba a lo mismo:
comportamiento tipo rootkit
Eso explicaba todo:
ps,top,netstat→ comprometidosEl proceso estaba… pero no lo podía ver
Hermoso desafío.
Contraataque
La solución fue ir por afuera:
Me traje binarios limpios (ps, top, netstat) desde un servidor no comprometido, los empaqueté y los ejecuté directamente en el infectado.
Y ahí sí…
./ps -AF | grep knerlApareció !!!
/usr/bin/bsd-port/knerl (PID 7372)
Ahí te tenía.
Primer golpe
kill -9 7372
Vuelvo corriendo a mirar el tráfico:
tcpdump -i any port 53…
Sigue habiendo tráfico sucio.
Pero algo cambió.
v1ns.9kpk.com desapareció
Quedaba solo 2.ip1100.com
Eso confirmaba que andaba otro cangrejo vivo.
el malware tenía más de un componente activo
Y la limpieza… todavía no había terminado.
Segundo componente malicioso
Si algo ya estaba claro, era esto: no estaba peleando contra un solo proceso.
Sigo revisando… y aparece otro candidato sospechoso un binario:
/usr/bin/sshupdate-bootsystem-insserv
Este tipo de nombres intenta simular procesos legítimos del sistema.
Se procedió nuevamente:
kill -9 <PID>
El momento de la verdad
Ahí sí… paro un segundo.
tiré un “padre nuestro”
y me fui directo a validar:
tcpdump -i any port 53Silencio.
Ni una consulta rara.
Ni v1ns.9kpk.com.
Ni 2.ip1100.com.
Tráfico limpio.
Después de horas peleando, el ruido había desaparecido.
Identificación de alcance
Con el servidor ya limpio, la siguiente pregunta era inevitable:
¿cuántos más están infectados?
Para determinar el alcance real, me apoyé en dos fuentes clave:
Logs DNS en Technitium
Tráfico de red desde firewall pfSense
Y fui directo a la base de datos del srv DNS:
SELECT DISTINCT client_ip
FROM dns_logs
WHERE qname = 'v1ns.9kpk.com'
AND timestamp >= 'fecha_inicio'
AND timestamp < 'fecha_fin';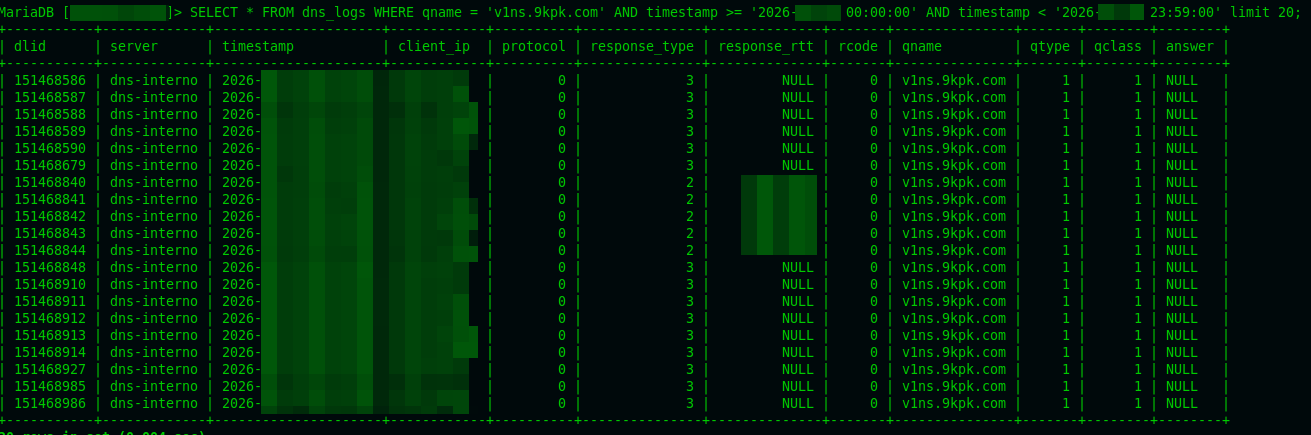
Solución
Con el incidente contenido, el foco ahora pasa a algo igual de importante: evitar que vuelva a ocurrir.
La estrategia definida es migrar este servicio a un entorno más controlado y seguro.
La idea es la siguiente:
Implementar un host base sobre Rocky Linux 9, correctamente hardenizado
Instalar Podman como motor de contenedores
Contenerizar el servicio dentro de una imagen basada en CentOS 7
¿Por qué CentOS 7?
Porque el servicio es legacy y tiene dependencias muy específicas que no son compatibles con versiones más nuevas. Forzar una actualización directa no es viable en este momento.
Indicadores de compromiso (IoC)
Dominios:
2.ip1100.comv1ns.9kpk.com
Binarios:
/usr/bin/bsd-port/knerl/usr/bin/sshupdate-bootsystem-insserv
Persistencia:
/etc/init.d/selinuxmodificado
Conclusión
Al momento de escribir este artículo, la investigación sigue en curso.
Todavía no está del todo claro cuál fue el vector inicial de infección ni cómo se propagó hacia otros servidores. La hipótesis más fuerte apunta a un ingreso desde Internet, ya que los servidores afectados son sistemas internos que, en teoría, no deberían estar expuestos y tampoco tienen internet.
Ahí es donde aparece la duda más interesante:
¿en algún momento existió una exposición no controlada? Un NAT temporal, una apertura puntual, alguna configuración que haya quedado habilitada más tiempo del debido… es una posibilidad que no se puede descartar.
Lo que sí parece poco probable es un origen interno mediante dispositivos físicos (como pendrives u otros medios), ya que no hay indicios que apunten en esa dirección.
Hoy por hoy, la única puerta lógica sigue siendo Internet.
Mientras tanto, continúo revisando logs, correlacionando eventos y tratando de determinar el alcance real de la infección.
Seguramente este análisis no termine acá:
si aparecen nuevos hallazgos, evaluaré si hacer una segunda parte o actualizar esta misma entrada con más información.
Porque si algo está claro, es que el incidente ya fue contenido…
pero la investigación recién empieza.
Si querés compartir tu experiencia, escribime a: valerkasystem@protonmail.com
- Valerka
Montevideo, Uruguay
¿Qué es una botnet? - Actualización post-análisis
Esta es la segunda parte del post, luego de haber profundizado en el análisis y confirmado que el malware detectado pertenece a la familia BillGates (también conocida como Elknot), una botnet modular dirigida a sistemas Linux.
No voy a reescribir aquí qué es una botnet ni cómo funciona paso a paso —hay material excelente ya publicado—, pero sí quiero dejar un par de ideas clave para contextualizar lo que enfrentamos y por qué este hallazgo cambia la perspectiva del incidente.
Una botnet (red de bots) es un conjunto de dispositivos comprometidos que, sin conocimiento de sus administradores, son controlados remotamente por un actor malicioso. Estos sistemas "zombis" se utilizan para:
Amplificar ataques DDoS, saturando servicios con tráfico coordinado.
Enviar spam masivo, aprovechando la reputación de dominios legítimos.
Minar criptomonedas en segundo plano, consumiendo recursos.
Robar credenciales y datos sensibles, actuando como puerta de entrada a redes internas.
Propagarse lateralmente, infectando otros sistemas dentro del mismo entorno.
En el caso específico de BillGates/Elknot, estamos ante una amenaza particularmente sigilosa:
Escrita en C, modular y diseñada para Linux.
Se camufla como procesos del sistema
knerlsimulandokernel.Persiste mediante servicios falsos
/etc/init.d/selinuxmodificado.Se comunica con múltiples dominios C2 para recibir instrucciones.
Emplea técnicas rootkit para ocultar procesos y binarios.
Todo esto explica por qué el análisis inicial fue tan desafiante: no era solo tráfico raro, era un actor con capacidad de evasión y persistencia.
Si querés profundizar en el tema, te recomiendo este artículo muy completo: