El día que movimos un cable y congelamos medio Proxmox: Storage GlusterFS
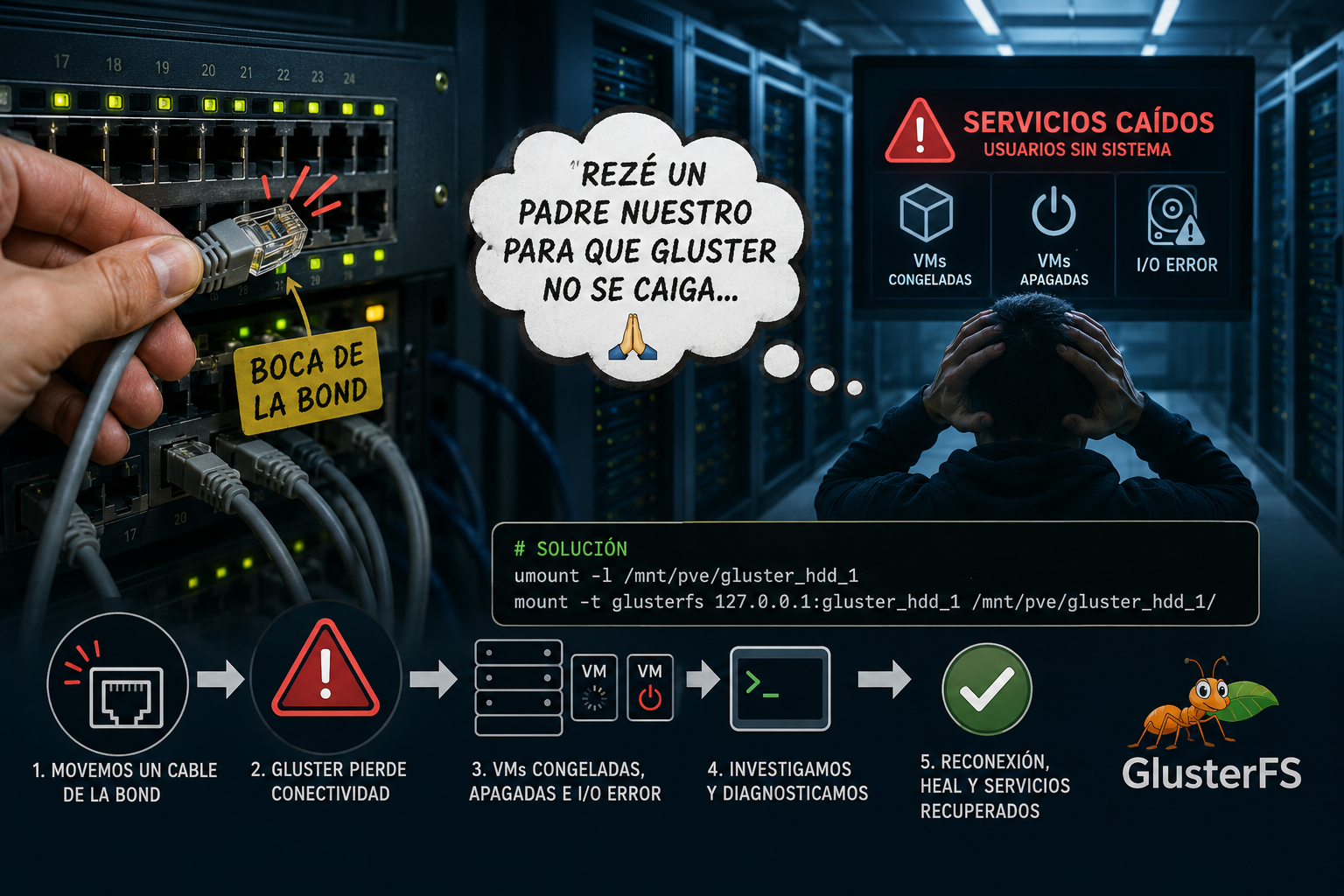 Hoy me tocó vivir uno de esos casos donde un simple movimiento físico termina escalando a una caída completa de servicios 😅
Hoy me tocó vivir uno de esos casos donde un simple movimiento físico termina escalando a una caída completa de servicios 😅
Fuimos al datacenter a realizar una tarea de relevamiento, siguiendo cables de red para identificar hacia qué puertos de los switches estaban conectados los servidores.
Mientras seguíamos uno de los cables, veo que mi compañero lo mueve y noto algo raro: la ficha RJ45 se movía dentro de la boca del switch. En ese momento me dice:
“esa es la boca de la BOND…”
Ahí recé un Padre Nuestro esperando que GlusterFS no perdiera conectividad y que los servicios siguieran vivos pero no sirvió de nada.
A los pocos segundos empezaron a llamarnos: “No funciona nada”, “Los usuarios quedaron sin sistema”
Volvimos corriendo a la oficina y comenzamos a investigar.
Entramos a Proxmox y encontramos:
VMs apagadas
otras congeladas
errores de I/O en discos
Eso ya apuntaba fuerte a problemas de almacenamiento distribuido con GlusterFS.
Primeras verificaciones
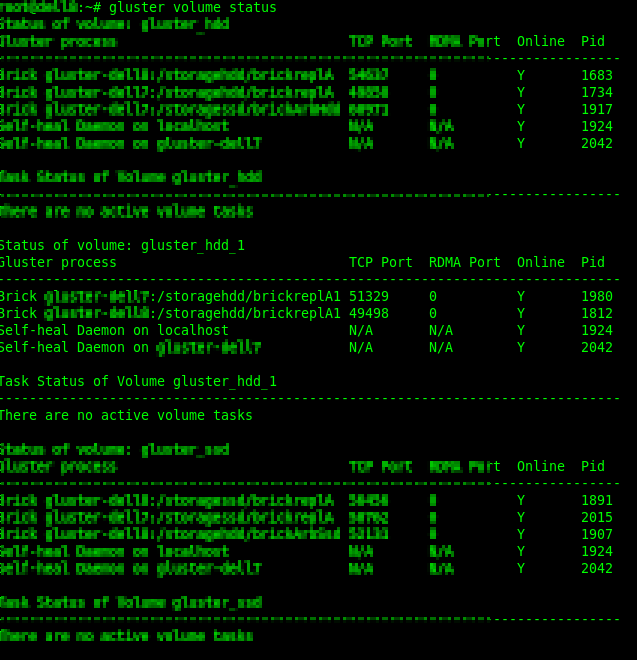
Verificar estado del volumen:
gluster volume statusBuscar: bricks offline, puertos en N/A, procesos muertos
Revisar Estado del servicio:
systemctl status glusterd.serviceServidor físico1:
May 12 11:41:29 server1 glustershd[2042]:
[rpc-clnt-ping.c:152:rpc_clnt_ping_timer_expired]
server <server1-IP>:24007 has not responded in the last 42 seconds, disconnecting.Servidor físico2:
May 12 11:37:21 server2 glustershd[1924]:
[rpc-clnt-ping.c:152:rpc_clnt_ping_timer_expired]
server <server2-IP>:24007 has not responded in the last 42 seconds, disconnecting.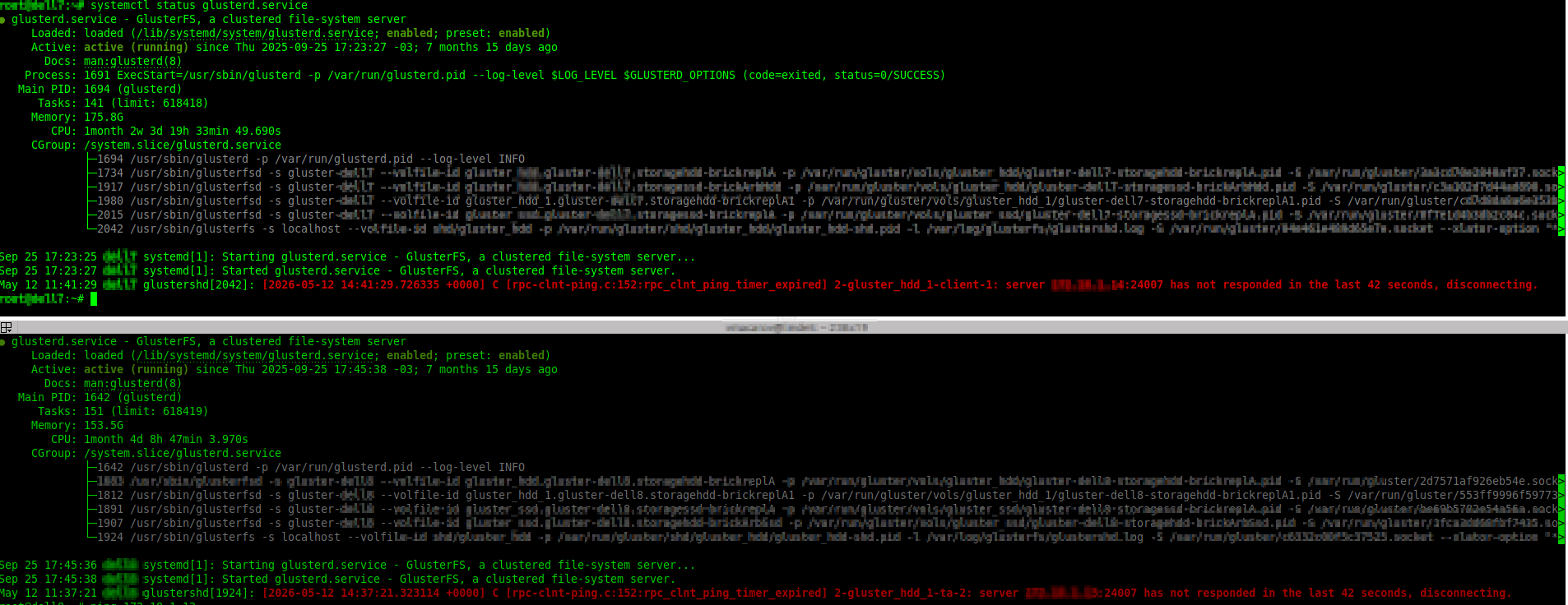
El síntoma raro
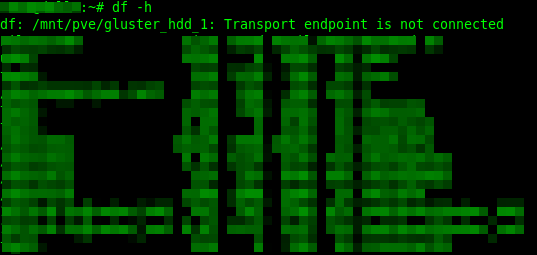
Si bien el punto de montaje aparecía montado:
mount | grep glusterMostraba:
127.0.0.1:gluster_hdd_1 on /mnt/pve/gluster_hdd_1 type fuse.glusterfs Pero
Pero df -h devolvía:
df: /mnt/pve/gluster_hdd_1: Transport endpoint is not connectedAhí quedó confirmado que el mount de Gluster quedó colgado después de la pérdida de conectividad.
Solución aplicada
Desmontar el endpoint colgado:
umount -l /mnt/pve/gluster_hdd_1Volver a montar:
mount -t glusterfs 127.0.0.1:gluster_hdd_1 /mnt/pve/gluster_hdd_1/Validaciones posteriores
Verificar peers:
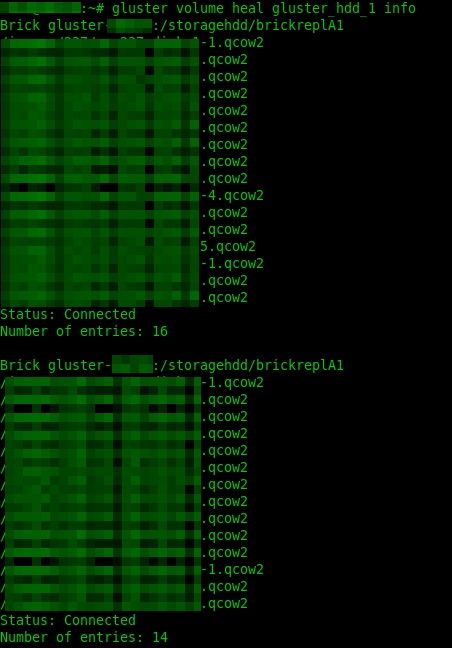
gluster peer statusVerificar heal pendiente:
gluster volume heal gluster_hdd_1 infoEl heal mostraba varios discos .qcow2 pendientes de sincronización entre bricks.
Conclusión y lección aprendida
En entornos con storage distribuido, un simple falso contacto físico puede terminar congelando VMs, generando errores de I/O y dejando usuarios sin poder trabajar en cuestión de segundos.
Lo más llamativo de este incidente es que el movimiento de un único cable no debería haber afectado de esta manera a un storage donde están los servicios críticos.
Eso nos deja una nueva línea de investigación: entender por qué la redundancia esperada no absorbió la falla como debía hacerlo.
Porque en teoría:
la BOND debería tolerar la caída de un enlace,
GlusterFS debería mantener disponibilidad entre nodos,
y la infraestructura crítica no debería verse afectada por mover un cable durante un relevamiento.
Pero la realidad demostró otra cosa.
¡Salud y buen blogging!
— Valerka (Montevideo, Uruguay)
¿Te gustó el post? ¿Tenés dudas, comentarios o querés compartir tu experiencia?
Escribime a: valerkasystem@protonmail.com — ¡Siempre leo los mails y trato de responder cuando puedo!