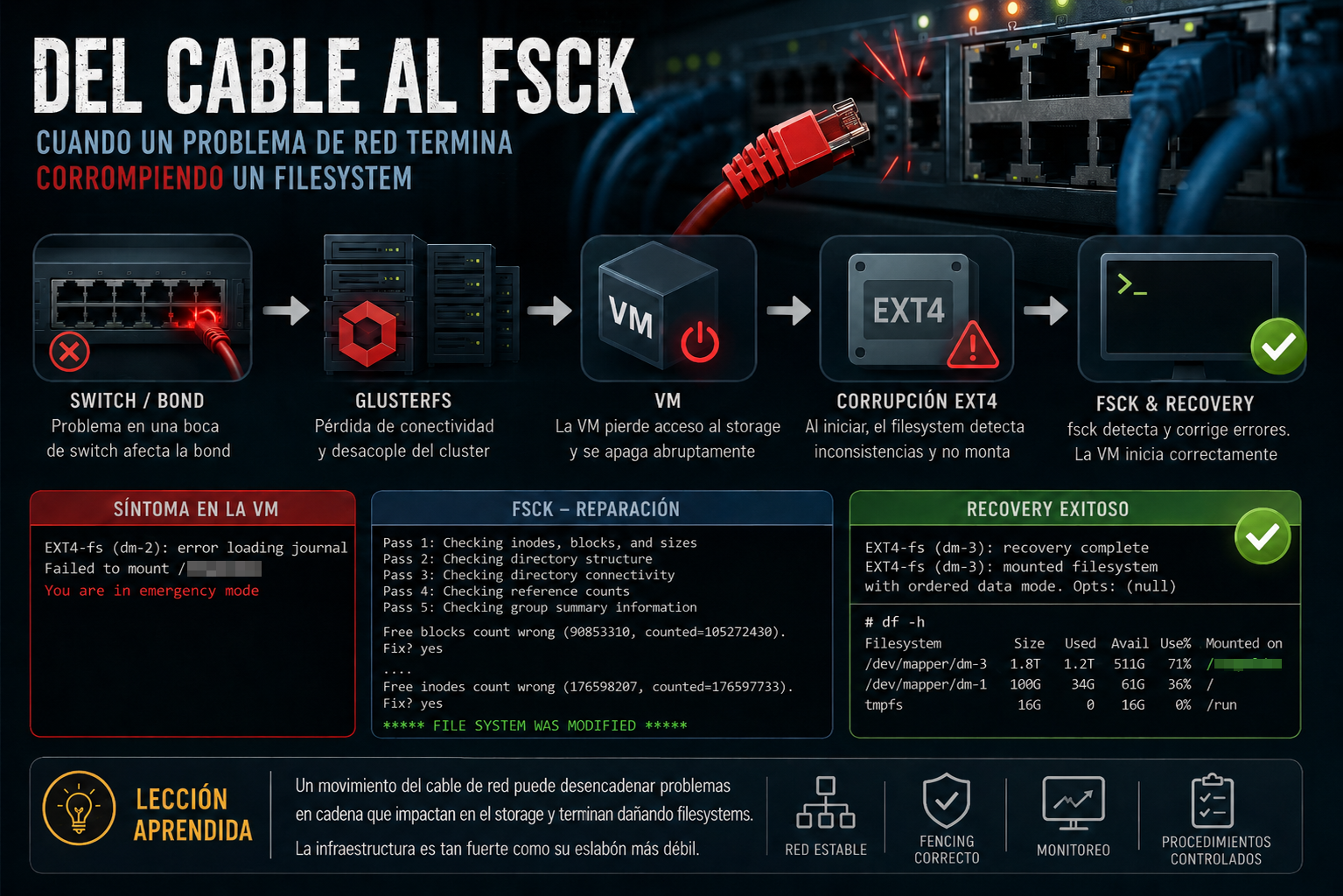
El coletazo del incidente en GlusterFS: corrupción EXT4 y el fsck que salvó la VM
 En el artículo anterior El día que movimos un cable y congelamos medio Proxmox: Storage GlusterFS conté cómo un problema aparentemente simple —mover un cable en una bond de red— terminó congelando parte de nuestro cluster Proxmox con storage distribuido en GlusterFS.
En el artículo anterior El día que movimos un cable y congelamos medio Proxmox: Storage GlusterFS conté cómo un problema aparentemente simple —mover un cable en una bond de red— terminó congelando parte de nuestro cluster Proxmox con storage distribuido en GlusterFS.
El incidente principal parecía terminado una vez recuperada la conectividad y estabilizado el storage. Pero faltaba el segundo acto.
Porque en infraestructura, muchas veces el problema más peligroso no es el corte inicial.
Es el daño silencioso que queda después.
El síntoma apareció recién al día siguiente
Horas después del incidente con GlusterFS, encendimos una VM que había quedado apagada abruptamente durante el problema del storage.
La VM no arrancó normalmente.
En consola de Proxmox apareció algo así:
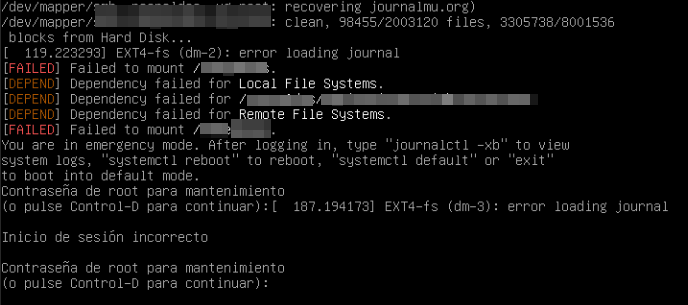
EXT4-fs (dm-2): error loading journal
Failed to mount /<nombreDirectorioAfectado>
You are in emergency modeLinux había entrado automáticamente en emergency mode porque no podía montar uno de los volúmenes.
El filesystem EXT4 detectó corrupción en el journal.
El detalle importante: el problema no estaba en la VM
Y esto es clave entenderlo.
La VM no “se rompió sola”.
El problema original ocurrió más abajo:
una falla en la bond del switch,
afectó conectividad del cluster,
impactó GlusterFS,
la VM perdió acceso consistente al storage,
y terminó apagándose abruptamente.
El daño al filesystem fue una consecuencia del problema de infraestructura anterior.
El arranque en emergency mode
La VM quedaba detenida esperando intervención manual (como se muestra en la imagen anterior).
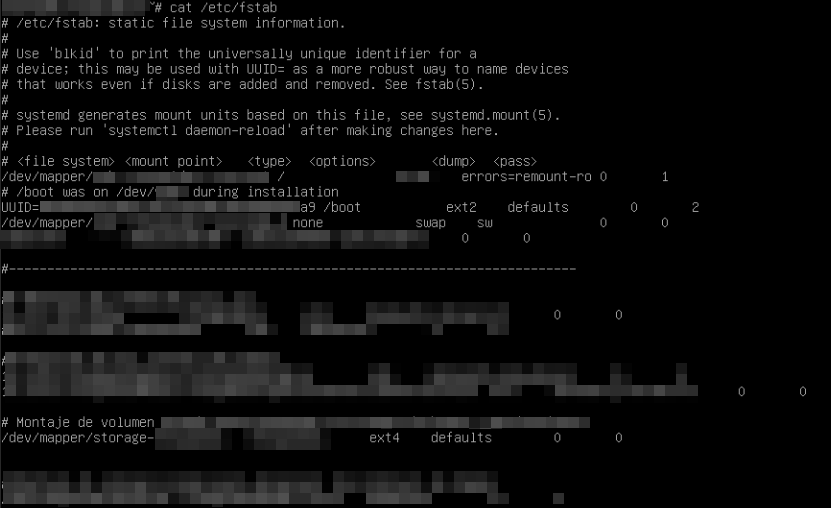
Primero identificamos el volumen afectado:
lsblk
cat /etc/fstabLuego ejecutamos fsck sobre el volumen comprometido.
En este caso era un LV montado como /<nombreDirectorioAfectado>.
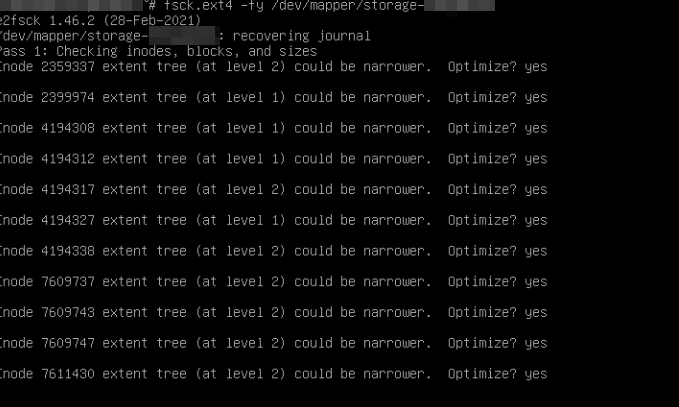
Ejecutando fsck
El comando fue:
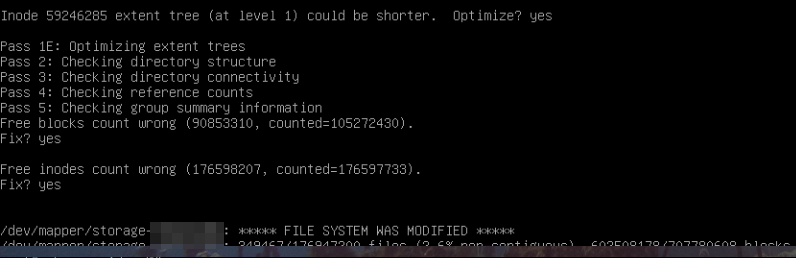
fsck.ext4 -fy /dev/mapper/storage-<nombreVolumen>Y ahí aparecieron los clásicos mensajes que nunca querés ver en producción:
Free blocks count wrong
Free inodes count wrongEl filesystem tenía inconsistencias internas.
Por suerte, el journal todavía era recuperable y fsck logró corregir todo automáticamente.
Al finalizar:
FILE SYSTEM WAS MODIFIEDY sinceramente, esa línea fue un alivio.
Porque significa:
encontró corrupción,
logró repararla,
y el filesystem volvió a un estado consistente.
Reinicio y validación
Después del fsck reiniciamos la VM.
El sistema volvió a levantar normalmente.
Validamos:
df -h,montaje correcto de/<nombreDirectorioAfectado>,logs de EXT4:
y
dmesg.
El kernel confirmó:
EXT4-fs (dm-3): recovery completeY lo más importante: no aparecieron errores de I/O ni corrupción adicional.


Conclusión
Este incidente también dejó algo claro a nivel operativo:
el relevamiento y reorganización del cableado del datacenter no puede volver a hacerse sobre infraestructura en producción sin una ventana controlada. Más allá de que el problema inicial pareció menor, terminó generando efectos en cadena sobre la red, el storage distribuido y finalmente sobre los filesystems de algunas VMs. Por ese motivo, el próximo relevamiento deberá planificarse correctamente, realizarse durante un fin de semana y con apagado controlado de los equipos involucrados, minimizando riesgos sobre la operación. Sobre todo considerando que actualmente estamos en proceso de planificación para migrar el datacenter a otra ubicación física, donde este tipo de tareas van a ser inevitables y van a requerir todavía más control y coordinación.
¡Salud y buen blogging!
— Valerka (Montevideo, Uruguay)
¿Te gustó el post? ¿Tenés dudas, comentarios o querés compartir tu experiencia?
Escribime a: valerkasystem@protonmail.com — ¡Siempre leo los mails y trato de responder cuando puedo!